Bayesian Statistics: The Science of Updating Beliefs with Data
What is Bayesian Statistics?
Bayesian statistics is a mathematical approach to statistical inference that allows us to update our knowledge about unknown parameters as new data becomes available. It is based on Bayes' theorem, a mathematical formula that describes how to update the probability of a hypothesis when given evidence.
At its core, Bayesian statistics differs from classical (frequentist) statistics in its interpretation of probability. In the Bayesian framework, probability represents a degree of belief or confidence, rather than a long-run frequency. This fundamental difference allows Bayesian methods to incorporate prior knowledge and provide probabilistic answers to specific questions of interest.
The key components of Bayesian statistics include:
- Prior distribution: Represents our beliefs about parameters before seeing the data
- Likelihood function: Describes the probability of observing the data given specific parameter values
- Posterior distribution: The updated belief about parameters after incorporating the data
- Predictive distributions: Forecasts for future observations based on current knowledge
The Bayesian approach allows for more intuitive answers to questions, quantifies uncertainty explicitly, and provides a natural framework for sequential learning as new data arrives.
Bayes' Theorem: The Foundation
The Mathematical Formula
Bayes' theorem, attributed to Reverend Thomas Bayes (1701-1761), provides the mathematical foundation for Bayesian statistics. The theorem states:
Where:
- P(θ|D) is the posterior probability of the parameters θ given the observed data D
- P(D|θ) is the likelihood of observing data D given parameters θ
- P(θ) is the prior probability of parameters θ before observing data
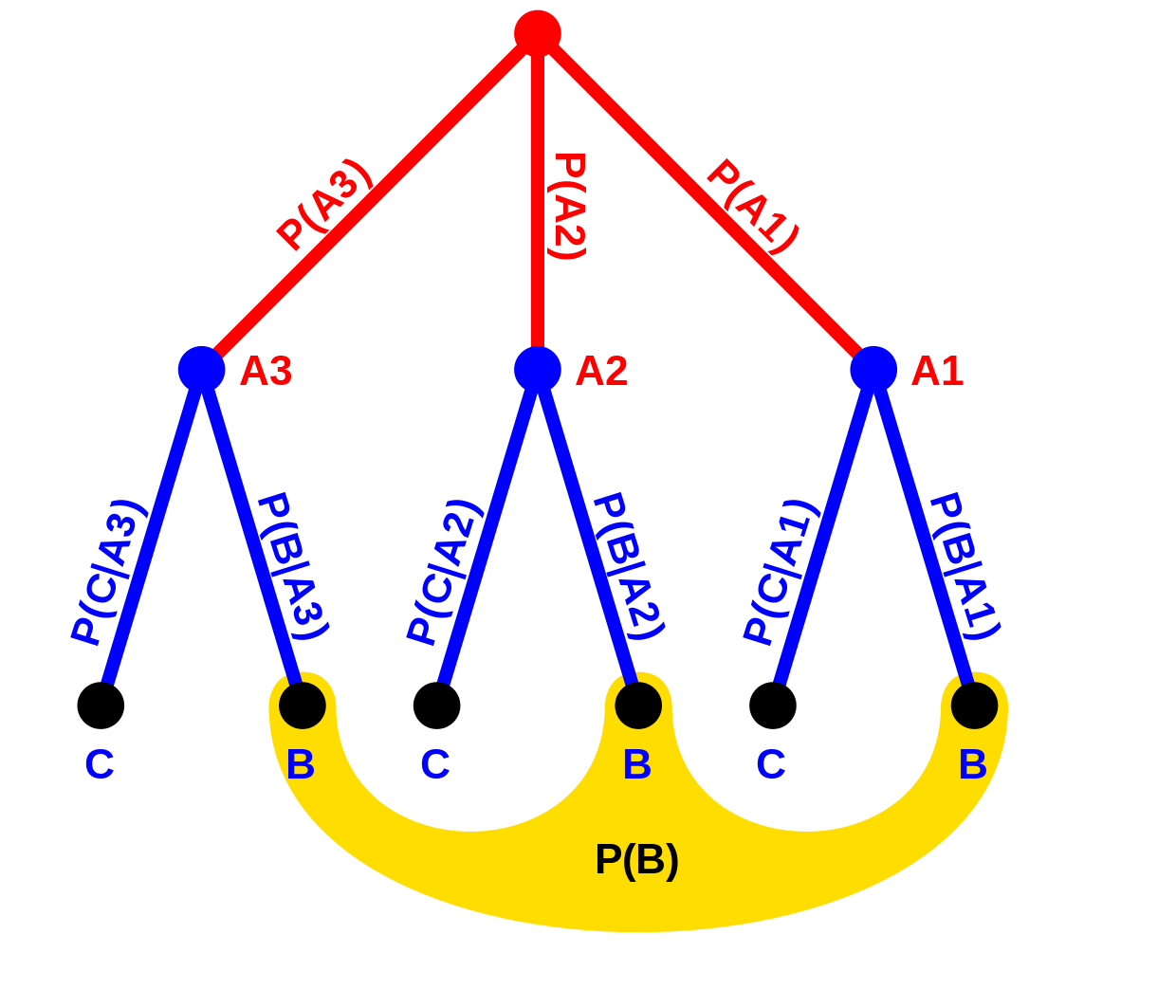
- P(D) is the marginal likelihood or evidence, calculated as the integral of the likelihood times the prior over all possible parameter values
A Simple Example
Consider testing for a disease that affects 1% of the population with a test that is 95% accurate (both sensitivity and specificity).
If a person tests positive, what is the probability they have the disease?
Prior probability: P(Disease) = 0.01 (1% population prevalence)
Likelihood: P(Positive|Disease) = 0.95 (95% test sensitivity)
Also needed: P(Positive|No Disease) = 0.05 (5% false positive rate)
Evidence: P(Positive) = P(Positive|Disease) × P(Disease) + P(Positive|No Disease) × P(No Disease)
P(Positive) = 0.95 × 0.01 + 0.05 × 0.99 = 0.0095 + 0.0495 = 0.059
Posterior probability: P(Disease|Positive) = (0.95 × 0.01) / 0.059 ≈ 0.16 or 16%
This classic example demonstrates the importance of accounting for both prior probabilities and likelihood ratios. Despite the test's high accuracy, the posterior probability of disease given a positive test is only about 16%, not 95% as many might intuitively guess. This illustrates how Bayesian reasoning can lead to counterintuitive but correct conclusions.
Historical Context
Thomas Bayes never published his theorem during his lifetime. His work was discovered and published posthumously by Richard Price in 1763. The theorem was further developed by Pierre-Simon Laplace, who independently rediscovered it and applied it to many problems in celestial mechanics, medical statistics, and reliability.
For much of the 20th century, Bayesian statistics was overshadowed by frequentist methods due to computational limitations and philosophical debates. The "Bayesian revolution" began in the late 20th century, fueled by increases in computational power and the development of Markov Chain Monte Carlo (MCMC) methods that made complex Bayesian calculations feasible.
Prior Distributions
The prior distribution represents our beliefs about the parameters before observing any data. It is one of the most distinctive features of Bayesian statistics and also one of its most controversial aspects.
Types of Priors
- Informative Priors: Based on available information such as previous studies, expert opinion, or physical constraints. These priors express specific, substantive information about the parameters.
- Weakly Informative Priors: Provide some regularization and stability but don't dominate the posterior. They express general knowledge rather than specific information about parameters.
- Non-informative Priors: Designed to have minimal impact on the posterior, allowing the data to "speak for itself." Examples include uniform priors and Jeffreys' priors.
- Conjugate Priors: Priors that, when combined with certain likelihood functions, produce posteriors of the same distribution family. These are mathematically convenient and were especially important before modern computational methods.
- Hierarchical Priors: Priors that themselves depend on hyperparameters, which have their own prior distributions. These are useful for complex models and partial pooling of information across groups.
Common Prior Distributions
For different types of parameters, certain prior distributions are commonly used:
- For proportions: Beta distribution (conjugate to binomial likelihood)
- For means with known variance: Normal distribution (conjugate to normal likelihood)
- For variances: Inverse-Gamma or Half-Cauchy distributions
- For count parameters: Gamma or Poisson distributions
- For multivariate parameters: Multivariate normal, Wishart, or Dirichlet distributions
Sensitivity Analysis
Because the choice of prior can influence results, especially with small sample sizes, it's important to assess how sensitive the conclusions are to the prior specification. Approaches include:
- Comparing results with different reasonable priors
- Using increasingly vague priors to see if results converge
- Formal sensitivity measures that quantify the influence of the prior
- Power prior approaches that allow data-dependent prior weighting
Likelihood Functions
The likelihood function represents how probable the observed data is under different parameter values. It forms the bridge between the data and the parameters in the Bayesian framework.
Definition and Properties
For a dataset D and parameter θ, the likelihood function L(θ; D) is proportional to the probability of observing D given θ:
Key properties of likelihood functions include:
- The likelihood is not a probability distribution over θ; it need not integrate to 1
- Only the relative values of the likelihood matter, not absolute values
- For independent observations, the likelihood is the product of individual observation likelihoods
- For computational reasons, we often work with the log-likelihood, which converts products to sums
Common Likelihood Functions
Different types of data require different likelihood functions:
- Binary outcomes: Bernoulli or binomial likelihood
- Count data: Poisson, negative binomial, or multinomial likelihood
- Continuous measurements: Normal, Student's t, or exponential likelihood
- Survival data: Exponential, Weibull, or Cox proportional hazards likelihood
- Categorical data: Multinomial or Dirichlet-multinomial likelihood
The Likelihood Principle
The likelihood principle states that all evidence about the parameter from the observed data is contained in the likelihood function. Two datasets with proportional likelihood functions should lead to the same inferences about θ.
This principle is automatically respected in Bayesian statistics but is violated by some frequentist methods. It has important implications for experimental design and analysis, particularly regarding:
- Stopping rules in sequential experiments
- Missing data mechanisms
- Optional stopping in hypothesis testing
Posterior Distribution
The posterior distribution is the updated belief about the parameters after observing the data. It combines the prior distribution and the likelihood function through Bayes' theorem.
Interpretation and Usage
The posterior distribution P(θ|D) represents our complete state of knowledge about the parameters given the data. It allows us to:
- Calculate point estimates (mean, median, mode) of parameters
- Construct credible intervals to quantify parameter uncertainty
- Test hypotheses by calculating posterior probabilities
- Make predictions for future observations
- Perform decision analysis by integrating over parameter uncertainty
Posterior Summaries
Since the posterior is a probability distribution, we typically summarize it using:
- Point estimates:
- Posterior mean: E[θ|D] - minimizes expected squared error
- Posterior median: minimizes expected absolute error
- Posterior mode (MAP estimate): maximizes posterior density
- Interval estimates:
- Credible intervals: intervals containing a specified probability mass of the posterior
- Highest posterior density (HPD) intervals: shortest intervals with specified probability
- Equal-tailed intervals: equal probability in each tail
- Full distribution: For complex decisions or predictions, the entire posterior may be used
Bayesian Credible vs. Frequentist Confidence Intervals
A 95% Bayesian credible interval has a 95% probability of containing the true parameter value, given the observed data. This is different from a 95% frequentist confidence interval, which would contain the true parameter in 95% of repeated experiments.
The Bayesian interpretation is often more intuitive and directly answers the question researchers typically want to ask: "What is the probability that the parameter lies in this range?" However, it depends on the choice of prior, while confidence intervals don't incorporate prior information.
In many cases with large samples or uninformative priors, Bayesian credible intervals and frequentist confidence intervals can be numerically similar, though their interpretations remain fundamentally different.
Computational Methods
For many real-world problems, the posterior distribution cannot be derived analytically. Computational methods have therefore become central to practical Bayesian statistics.
Markov Chain Monte Carlo (MCMC)
MCMC methods generate samples from the posterior distribution by constructing a Markov chain whose stationary distribution is the target posterior. Key MCMC algorithms include:
- Metropolis-Hastings: Proposes moves based on a proposal distribution and accepts or rejects them probabilistically based on the posterior ratios
- Gibbs Sampling: Updates one parameter at a time, sampling from its conditional posterior given all other parameters
- Hamiltonian Monte Carlo (HMC): Uses gradient information to propose more efficient moves, reducing random walk behavior and autocorrelation
- No-U-Turn Sampler (NUTS): An extension of HMC that automatically tunes the step size and number of steps
MCMC diagnostics are crucial to ensure the chain has:
- Converged to the stationary distribution (using multiple chains, Gelman-Rubin statistic)
- Explored the posterior space adequately (effective sample size, autocorrelation)
- Mixed well (trace plots, acceptance rates)
Variational Inference
Variational inference approximates the posterior with a simpler distribution (like a Gaussian) by minimizing the Kullback-Leibler divergence between the approximation and the true posterior. It is typically faster than MCMC but may be less accurate, especially for complex, multimodal posteriors.
Methods include:
- Mean-field variational inference: Assumes independence between parameters in the approximating distribution
- Stochastic variational inference: Uses stochastic optimization for large datasets
- Automatic differentiation variational inference (ADVI): Automatically transforms constrained variables and uses automatic differentiation for optimization
Other Computational Approaches
- Laplace Approximation: Approximates the posterior with a multivariate normal centered at the MAP estimate
- Integrated Nested Laplace Approximation (INLA): Efficient for latent Gaussian models
- Sequential Monte Carlo / Particle Filters: For sequential data and online updating
- Approximate Bayesian Computation (ABC): For models with intractable likelihoods
- Conjugate computation: Exact analytical solutions for specific prior-likelihood combinations
Bayesian Model Selection and Comparison
Bayesian statistics provides principled approaches to compare models and select the most appropriate one for the data.
Bayesian Model Comparison
The key quantities for Bayesian model comparison are:
- Marginal likelihood (evidence): P(D|M) = ∫ P(D|θ,M) × P(θ|M) dθ, the probability of the data under a given model, integrating over all parameter values
- Bayes factors: The ratio of marginal likelihoods for two competing models, measuring the relative evidence they provide
- Posterior model probabilities: P(M|D) ∝ P(D|M) × P(M), the probability of each model given the data and prior model probabilities
Information Criteria
When the marginal likelihood is difficult to compute, various information criteria can be used as approximations:
- Deviance Information Criterion (DIC): Particularly useful for hierarchical models and MCMC outputs
- Widely Applicable Information Criterion (WAIC): A fully Bayesian approach that uses the entire posterior distribution
- Leave-One-Out Cross-Validation (LOO-CV): Estimates out-of-sample predictive accuracy
- Bayesian Information Criterion (BIC): An asymptotic approximation to the log marginal likelihood
Bayesian Model Averaging
Rather than selecting a single "best" model, Bayesian model averaging (BMA) combines predictions from multiple models, weighted by their posterior probabilities:
Where Ỹ represents future observations, and the sum is over all models Mk.
BMA has several advantages:
- Accounts for model uncertainty in predictions and inferences
- Often produces better predictive performance than any single model
- Provides more realistic uncertainty quantification
Applications of Bayesian Statistics
Data Science and Machine Learning
- Bayesian Neural Networks: Add uncertainty quantification to neural network predictions
- Gaussian Processes: Flexible non-parametric models for regression and classification
- Bayesian Optimization: Efficient exploration of parameter spaces for hyperparameter tuning
- Topic Models: Latent Dirichlet Allocation and other Bayesian methods for document analysis
- Causal Inference: Bayesian networks and structural equation models for causal relationships
Science and Research
- Clinical Trials: Adaptive designs, benefit-risk assessment, and subgroup analysis
- Genomics: Gene expression analysis, genome-wide association studies
- Ecology: Species distribution models, capture-recapture studies, population dynamics
- Astronomy: Image processing, cosmological parameter estimation
- Climate Science: Climate model calibration, paleoclimate reconstruction
Business and Economics
- Marketing: Customer behavior modeling, A/B testing, marketing mix models
- Reliability Analysis: Failure modeling, anomaly detection, and uncertainty-aware forecasting
- Econometrics: Time series forecasting, causal impact analysis
- Supply Chain: Demand forecasting, inventory optimization
- Pricing: Dynamic pricing strategies, elasticity estimation
Engineering and Technology
- Reliability Analysis: Failure time prediction, maintenance scheduling
- Signal Processing: Filtering, source separation, spectral analysis
- Computer Vision: Object detection, image segmentation with uncertainty
- Natural Language Processing: Language models, sentiment analysis
- Recommender Systems: Personalized recommendations with Thompson sampling
Software Tools for Bayesian Analysis
Modern Bayesian analysis is enabled by a rich ecosystem of software tools and programming languages.
Probabilistic Programming Languages
- Stan: A statically typed language for statistical modeling, particularly efficient for hierarchical models
- PyMC: Python library for probabilistic programming focusing on MCMC and variational inference
- JAGS: Just Another Gibbs Sampler, focusing on Gibbs sampling for graphical models
- Turing.jl: A Julia library offering flexible model specification and multiple inference algorithms
- TensorFlow Probability / Edward2: Bayesian modeling and inference built on TensorFlow
R Packages
- brms: Bayesian Regression Models using Stan, with familiar R formula interface
- rstanarm: Applied regression modeling via Stan
- MCMCpack: Provides MCMC samplers for common Bayesian models
- bayesm: Bayesian inference for marketing and micro-econometrics
- bayestestR: Utilities for Bayesian model checking and result interpretation
Resources for Learning Bayesian Statistics
For those new to Bayesian statistics, several resources can help build understanding:
- Textbooks: "Statistical Rethinking" by Richard McElreath, "Bayesian Data Analysis" by Gelman et al., "Doing Bayesian Data Analysis" by John Kruschke
- Online Courses: "Statistical Rethinking" course (available on YouTube), Coursera's "Bayesian Statistics" specialization, DataCamp's Bayesian courses
- Tutorials and Case Studies: PyMC and Stan documentation include extensive examples
- Communities: Stan forums, PyMC Discourse, Cross Validated (Stack Exchange)
Frequently Asked Questions
What is Bayesian Statistics?
Bayesian statistics is a mathematical approach to statistical inference that allows us to update our knowledge about unknown parameters as new data becomes available, based on Bayes' theorem. Unlike frequentist statistics, it treats probability as a degree of belief or confidence rather than a long-run frequency, allowing for the incorporation of prior knowledge and providing probabilistic answers to specific questions.
What is Bayes' Theorem and how is it used?
Bayes' Theorem is expressed as P(θ|D) = P(D|θ) × P(θ) / P(D), where P(θ|D) is the posterior probability, P(D|θ) is the likelihood, P(θ) is the prior probability, and P(D) is the evidence. It's used to update probability estimates as new data becomes available, allowing for sequential learning and decision-making under uncertainty in fields ranging from medicine and science to artificial intelligence and reliability modeling.
What are prior and posterior distributions in Bayesian statistics?
Prior distributions represent our beliefs about parameters before observing data, which can be informative (based on previous knowledge), weakly informative, or non-informative. Posterior distributions are the updated beliefs after incorporating observed data, calculated by combining the prior distribution with the likelihood function using Bayes' theorem. The posterior serves as the foundation for Bayesian inference, prediction, and decision-making.
How does Bayesian statistics differ from frequentist statistics?
Bayesian statistics differs from frequentist approaches in several key ways: it interprets probability as a degree of belief rather than long-run frequency; it incorporates prior knowledge through prior distributions; it provides direct probability statements about parameters rather than relying on p-values and confidence intervals; it naturally handles small sample sizes and complex models; and it offers a framework for sequential updating as new data arrives.
What computational methods are used in Bayesian statistics?
Bayesian computation often uses Markov Chain Monte Carlo (MCMC) methods like Metropolis-Hastings algorithm, Gibbs sampling, and Hamiltonian Monte Carlo to sample from complex posterior distributions. Other approaches include variational inference (for approximating posteriors), integrated nested Laplace approximation (INLA), and approximate Bayesian computation (ABC). Modern implementations use probabilistic programming languages like Stan, PyMC, and JAGS to automate these complex computations.
What are some practical applications of Bayesian statistics?
Bayesian statistics has numerous practical applications: in machine learning for probabilistic models and robust optimization; in medicine for clinical trials, diagnostic testing, and personalized treatment; in reliability analysis and anomaly detection; in environmental science for climate modeling and ecological forecasting; in A/B testing for business decisions; and in natural language processing, computer vision, and other AI applications that require reasoning under uncertainty.
References
- Gelman, Carlin, Stern, Dunson, Vehtari, and Rubin. Bayesian Data Analysis. 2013.
- McElreath. Statistical Rethinking: A Bayesian Course with Examples in R and Stan. 2020.
Last reviewed: April 15, 2026
Maintained by MathCalculate Editorial as part of the public quantitative reference library.
Key topics covered: This article explores bayesian statistics, bayesian inference, prior distribution, posterior distribution, bayes theorem, probabilistic modeling, bayesian computational methods, and mcmc, together with real-world applications.